



By: Geeq on Aug 23, 2022
Background
A primary objective for using blockchain is to allow two (or more) people to look independently at a data entry, at their own convenience, and know whether they are able to rely on it or not. The data entry, recorded in a block of a blockchain, might be a transfer of payments or any other piece of information users might wish to share.
The type of data they may wish to see depends entirely on their needs and how applications are written. The blockchain itself does not care. To a blockchain, data is data. Blockchain protocols are written to determine if transactions should be included or not, whatever those transactions may be.
Topic
Today, we introduce the concept of a hash, which is used everywhere in the construction of blockchains. One might even say, blockchains are constantly rehashing the data. (This terrible pun was unavoidable, because it is very true. Someday, we will write another explainer for recursive hashes.)
Let’s focus on the basics and discuss four properties of a hash. We think we can convince you Geeq has found a way to make hashes so useful, the sky is the limit for the ways you can use Geeq Data.
Point #1: A hash is a method to compress a computer-readable data file.
Consider the banner image for this article. It is an image of a leopard lying in a tree. The image is represented as a .png file (portable network graphics file) and the file size is 534 kB (534,000 bytes).
The way to obtain a hash of a data file is to use a hashing function, which is a mathematical function. The hashing function needs an input in order to produce an output.
In this case, the image file is the input. Inputting this image file into a hashing function, is called “hashing it”, and it results in an output of fixed length. Regardless of the size of the input, the output from any given hashing function will always be the same length, which is convenient to know from a design standpoint.
In Geeq Data, the process is as simple as uploading a file and clicking a button that says “Hash it”. The mathematical operation happens in the background.
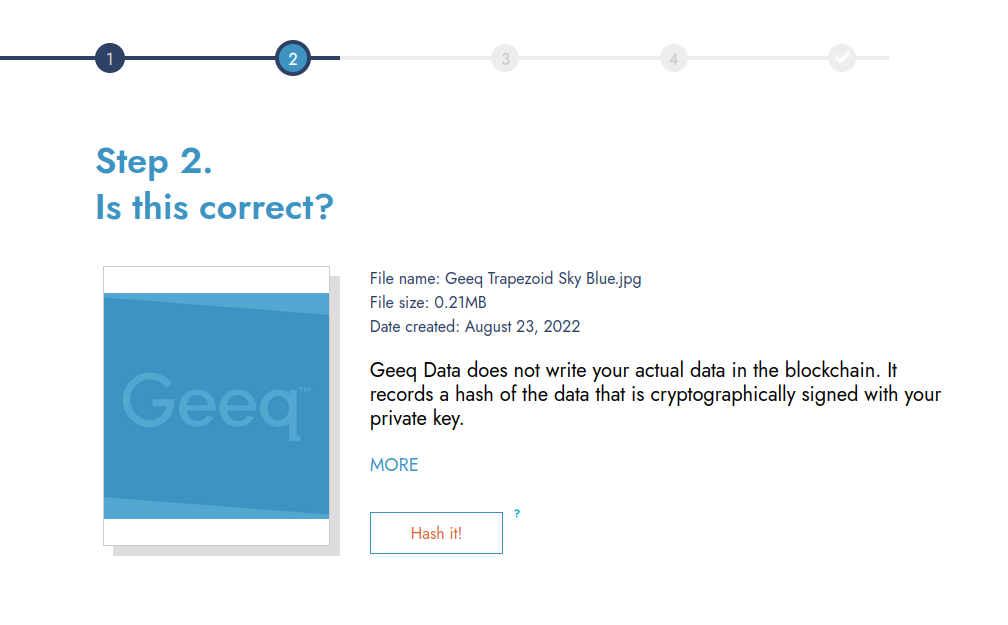
As you know, many data files are large, so the hash of the input file is usually much smaller than the original. The ubiquitous Secure Hash Algorithm “SHA”-256 returns a 32 byte (256 bit) binary string, regardless of the size of the input. The original image was 16,687.5 times larger.
Notice, a deployment of a Geeq Data product does not mean the full-sized file is stored in the blockchain. The message sent to the blockchain contains the hash of the file, not the file itself. This method helps to manage the size of the block and keeps the contents of your file private and stored wherever you like, e.g. stored on your own hard drive or on your company’s server.
Point #2: Even a slight change in the data results in a new and very different hash.
Every time you hash the exact same data, you will obtain the exact same hash. This makes sense: when you take the same input and use the same function, you will get the same hash as an output.
However, if you change the data even slightly and hash the new data (using the same function), you are almost guaranteed to get a very different hash as an output.
The images of the two leopards below are exactly the same except the one on the right has had a spot removed. Even though a small change was made, if you compare the hash on the left with the one on the right, the hashes themselves are completely different.
As a matter of vocabulary, the input is called a pre-image. The output is called a hash or, more formally, a hash digest. Two very similar pre-images led to two very different hashes.

Here are two more examples.


Suppose you care about whether the evidence in front of you (on the right) matches the original records kept (on the left). You have so much work to do, you are not interested in anything but separating records that match versus those you should flag.
Do you see how easy it is to check if the hashes are identical, instead of looking at the original data files side-by-side? That is one way the Geeq Data family of apps puts hashes to work for you.
Suppose you and a client have reviewed and agreed to a contract, which will be sent separately to each of you to sign. When each of you hash the agreed upon document and check it with the hash of the document you are supposed to sign, you know the document is the same and there is no reason to re-read the contract.
Now suppose your client has used a program to change one word in the contract. Mismatching hashes tell you there is a discrepancy, and you should investigate further.
Point #3: A hash is a snapshot of the data submitted at the time.
Another way to think about a hash is that it represents a snapshot of the data, frozen as it was when you hashed it. One reason to send a “message” or a “transaction” to a blockchain is to ask for it to be processed within a certain time period, because the order in which the transactions are received is of interest.
For example, let’s say you back into another car by accident. If the police take photos on the scene and use the Geeq Data web app to hash them and submit a police report, any photos the other driver tries to submit later will get flagged by the difference in hashes.
The advantage of having those photos hashed already on the blockchain is the insurance company would be able to search for the accident, compare the hashes of the photos, notice one is different, and investigate. The tangible result? The other driver will not be able to claim you caused more damage than you did, and your insurance premium may not go up (as much).
Of course, this is only one of many ways Geeq Data combines hashes with blockchain to save everyone time and money.
Point #4: You cannot look at a hash, in isolation, and determine what the original data was.
A property of hashing functions is that they are not invertible. Translation: even though the hashing function is known, an output gives no clues to the input. This was illustrated in the examples above.
When dealing with sensitive data, enterprises and data owners may prefer to send hashes of data to a blockchain as an alternative to opening their internal databases for scrutiny. By using Geeq Data’s webapp with a private blockchain, they can accomplish a lot with a little:
- Send an efficient snapshot (hash) of the data to the blockchain, e.g. for compliance or to protect against other claims, without disrupting normal enterprise systems. Because blocks are sequentially constructed, the hash in the block is recorded for safekeeping in a timely manner, without revealing the original data; and
- Search for and compare hashes as needed in the corresponding Block Explorer, using their own defined metadata tags. No one has to know what the original data is unless they already have the correct pre-image and have permission to access the blockchain to verify it for themselves.
Conclusion
Geeq is building the infrastructure for reliable and user-friendly web apps that use blockchain methods in easy to understand ways. With the Geeq Data family of apps, you and your data will receive all the benefits of the hardworking hash.
Geeq Data is the private blockchain solution for enterprise
Are you ready to learn more?
Go To Geeq DataTechnical Note:
A “collision” occurs when two inputs happen to result in exactly the same hash. In theory, these must be possible although extremely unlikely to occur when you’re looking for one.
The reason a collision must be possible is because there are ‘only’ 2256 possible hashes. (Each of the 256 bits can be either a 0 or a 1.) The reason an average user has little reason to worry about this in their typical use of Geeq Data is that, in order for someone to claim they have the true data that leads to the same hash as yours, each time they try to hash something, they have a 1 in 1072 chance of finding an alternative. (1 in 2256 is the same as 1 in 1072.)
Fun fact:
The leopard on the right is missing a spot between his neck and chin.
To learn more about Geeq, follow us and join the conversation.
@GeeqOfficial